Showing posts with label Windows. Show all posts
Showing posts with label Windows. Show all posts
Friday, 28 October 2011
ParaView 3.12.0 RC-3 available for download
ParaView 3.12.0 Release Candidate 3 binaries are available for download on the official page http://paraview.org/paraview/resources/software.html. It is a bug-fix release and the details can be found at http://www.paraview.org/Bug/changelog_page.php?version_id=85.
Thursday, 23 June 2011
New software updates including OpenFOAM
Recently there have been some interesting software updates including
1. OpenFOAM version 2.0.0
OpenCFD released OpenFOAM version 2.0.0 and many significant developments have been made. In parallel to the release of OpenFOAM 2.0.0, the git repository was updated to 2.0.x.
2. GeekoCFD 2
GeekoCFD 2 has been released.
3. VMware Fusion 3.1.3
VMware Fusion 3.1.3 (416484) has been release at the end of May. Bugs were fixed and more importantly, Ubuntu 11.04 has been officially supported. The previous version needed patches for its VMware tool because of its incompatibility to Linux Kernel 2.6.37/38.
4. Firefox 5
Mozilla greatly shortened its new version release periods. As a convention Microsoft IE team sent Mozilla a cupcake for launching Firefox 5.

Firefox has been updated automatically to this latest version on my Mac and all extensions work very well. On Windows there is only one exception, IE Tab Plus.
1. OpenFOAM version 2.0.0
OpenCFD released OpenFOAM version 2.0.0 and many significant developments have been made. In parallel to the release of OpenFOAM 2.0.0, the git repository was updated to 2.0.x.
2. GeekoCFD 2
GeekoCFD 2 has been released.
3. VMware Fusion 3.1.3
VMware Fusion 3.1.3 (416484) has been release at the end of May. Bugs were fixed and more importantly, Ubuntu 11.04 has been officially supported. The previous version needed patches for its VMware tool because of its incompatibility to Linux Kernel 2.6.37/38.
4. Firefox 5
Mozilla greatly shortened its new version release periods. As a convention Microsoft IE team sent Mozilla a cupcake for launching Firefox 5.
Firefox has been updated automatically to this latest version on my Mac and all extensions work very well. On Windows there is only one exception, IE Tab Plus.
Wednesday, 9 March 2011
ParaView 3.10.0 is released
The ParaView team has announced the availability of the ParaView 3.10.0 final binaries for download on the ParaView download page.
http://paraview.org/paraview/resources/software.html
I repost the Release Notes from the email list as follows:
ParaView 3.10
This release features notable developments, including mechanisms to incorporate advanced rendering techniques, improved support for readers and several usability enhancements and bug fixes.
For the 3.10 release, we have added 60 new readers. The new readers include: ANSYS, CGNS, Chombo, Dyna3D, Enzo, Mili, Miranda, Nastran, Pixie, Samrai, Silo, and Tecplot Binary. A full listing of supported readers can be found in the ParaView Users Guide. We also added the ability for developers to create ParaView reader plugins from previously developed VisIt reader plugins. You can find a full guide on how to do this on the VisIt Database Bridge: http://www.paraview.org/Wiki/VisIt_Database_Bridge.
With this release we have rewritten the ParaView User's Guide and are making it freely available for the first time. The complete guide can be obtained in the help system or online at:
http://paraview.org/Wiki/ParaView/Users_Guide/Table_Of_Contents.
We have included a Python-based calculator which makes it possible to write operations using Python. The Python calculator uses NumPy, which lets you use advanced functions such as gradients, curls, and divergence easily in expressions. Also the NumPy module is packaged in the ParaView binary and is importable from the ParaView Python shell.
There should also be a marked performance improvement for users dealing with large multi-block datasets. We have cleaned up the rendering pipeline to better handle composite datasets, avoiding the appending of all blocks into a single dataset as was done previously.
To better utilize multiple cores on modern multi-core machines, by default ParaView can now run using a parallel server, even for the built-in mode. This enables the use of all the cores for parallel data processing, without requiring the user to start a parallel server. ParaView binaries will also be distributed using an MPI implementation, making this feature available to users by simply downloading the binaries. Since this is an experimental feature, it is off by default, but users can turn it on by checking the Auto-MPI checkbox in the application settings dialog.
Additionally, the 3.10 release includes several usability enhancements. 3D View now supports smart context menus, accessed by right-clicking on any object in the 3D View to change its color, representation, color map and visibility. Left-clicking on an object in the 3D View makes it active in the pipeline browser. Within the spreadsheet view, sorting is now supported and an advanced parallel sorting algorithm ensures that none of the benefits of the spreadsheet view, such as streaming and selection, are sacrificed. Python tracing and macro controls are no longer hidden on the Python shell dialog and instead are now easily found on the Tools menu.
For developers interested in adding support for advanced multi-pass rendering algorithms to ParaView, this release includes a major refactoring of ParaView's rendering pipeline. View and representations have been redesigned and users should see improved performance in client-server mode from reduced interprocess communication during rendering.
LANL's MantaView interactive ray tracing plugin has been restructured to make it easier to use. Version 2.0 of the plugin is now multi-view capable and no longer requires ParaView to be run in a client/server configuration. Similarly both of LANL's streaming aware ParaView derived applications have been merged into ParaView proper in the form of a new View plugin. The underlying streaming algorithms have been rewritten to be more usable and extensible. Both plugins are available in standard binary package for the first time in this release.
For an exhaustive list of the new features and bug-fixes, please refer to the change log at: http://www.paraview.org/Bug/changelog_page.php.
As always, we rely on your feedback to make ParaView better. Please use http://paraview.uservoice.com/ or click on the "Tell us what you think" link on paraview.org to leave your feedback and vote for new features.
http://paraview.org/paraview/resources/software.html
I repost the Release Notes from the email list as follows:
ParaView 3.10
This release features notable developments, including mechanisms to incorporate advanced rendering techniques, improved support for readers and several usability enhancements and bug fixes.
For the 3.10 release, we have added 60 new readers. The new readers include: ANSYS, CGNS, Chombo, Dyna3D, Enzo, Mili, Miranda, Nastran, Pixie, Samrai, Silo, and Tecplot Binary. A full listing of supported readers can be found in the ParaView Users Guide. We also added the ability for developers to create ParaView reader plugins from previously developed VisIt reader plugins. You can find a full guide on how to do this on the VisIt Database Bridge: http://www.paraview.org/Wiki/VisIt_Database_Bridge.
With this release we have rewritten the ParaView User's Guide and are making it freely available for the first time. The complete guide can be obtained in the help system or online at:
http://paraview.org/Wiki/ParaView/Users_Guide/Table_Of_Contents.
We have included a Python-based calculator which makes it possible to write operations using Python. The Python calculator uses NumPy, which lets you use advanced functions such as gradients, curls, and divergence easily in expressions. Also the NumPy module is packaged in the ParaView binary and is importable from the ParaView Python shell.
There should also be a marked performance improvement for users dealing with large multi-block datasets. We have cleaned up the rendering pipeline to better handle composite datasets, avoiding the appending of all blocks into a single dataset as was done previously.
To better utilize multiple cores on modern multi-core machines, by default ParaView can now run using a parallel server, even for the built-in mode. This enables the use of all the cores for parallel data processing, without requiring the user to start a parallel server. ParaView binaries will also be distributed using an MPI implementation, making this feature available to users by simply downloading the binaries. Since this is an experimental feature, it is off by default, but users can turn it on by checking the Auto-MPI checkbox in the application settings dialog.
Additionally, the 3.10 release includes several usability enhancements. 3D View now supports smart context menus, accessed by right-clicking on any object in the 3D View to change its color, representation, color map and visibility. Left-clicking on an object in the 3D View makes it active in the pipeline browser. Within the spreadsheet view, sorting is now supported and an advanced parallel sorting algorithm ensures that none of the benefits of the spreadsheet view, such as streaming and selection, are sacrificed. Python tracing and macro controls are no longer hidden on the Python shell dialog and instead are now easily found on the Tools menu.
For developers interested in adding support for advanced multi-pass rendering algorithms to ParaView, this release includes a major refactoring of ParaView's rendering pipeline. View and representations have been redesigned and users should see improved performance in client-server mode from reduced interprocess communication during rendering.
LANL's MantaView interactive ray tracing plugin has been restructured to make it easier to use. Version 2.0 of the plugin is now multi-view capable and no longer requires ParaView to be run in a client/server configuration. Similarly both of LANL's streaming aware ParaView derived applications have been merged into ParaView proper in the form of a new View plugin. The underlying streaming algorithms have been rewritten to be more usable and extensible. Both plugins are available in standard binary package for the first time in this release.
For an exhaustive list of the new features and bug-fixes, please refer to the change log at: http://www.paraview.org/Bug/changelog_page.php.
As always, we rely on your feedback to make ParaView better. Please use http://paraview.uservoice.com/ or click on the "Tell us what you think" link on paraview.org to leave your feedback and vote for new features.
Tuesday, 21 September 2010
MATLAB 2010b supports NVIDIA CUDA-capable GPUs
From MATLAB 2010b, GPU support is available in Parallel Computing Toolbox. Using MATLAB for GPU computing lets you take advantage of GPUs without low-level C or Fortran programming.
MATLAB CUDA support provides the base for GPU-accelerated MATLAB operations and lets integrate existing CUDA kernels into MATLAB applications. However, as a restriction, MATLAB only supports GPUs with CUDA compute capability version 1.3 or higher, such as Tesla 10-series and 20-series GPUs. This limitation is not from a light decision; it is actually due to the double precision support and the IEEE-compliant maths implementation of the CUDA capability version 1.3. Please see this thread for more discussion.
MATLAB GPU computing capabilities include:
Introduction to MATLAB GPU Computing (Video)
MATLAB GPU Computing (Documentation)
MATLAB CUDA support provides the base for GPU-accelerated MATLAB operations and lets integrate existing CUDA kernels into MATLAB applications. However, as a restriction, MATLAB only supports GPUs with CUDA compute capability version 1.3 or higher, such as Tesla 10-series and 20-series GPUs. This limitation is not from a light decision; it is actually due to the double precision support and the IEEE-compliant maths implementation of the CUDA capability version 1.3. Please see this thread for more discussion.
MATLAB GPU computing capabilities include:
- Data manipulation on NVIDIA GPUs
- GPU-accelerated MATLAB operations
- Integration of CUDA kernels into MATLAB applications without low-level C or Fortran programming
- Use of multiple GPUs on the desktop (via the toolbox) and a computer cluster (via MATLAB Distributed Computing Server)
Introduction to MATLAB GPU Computing (Video)
MATLAB GPU Computing (Documentation)
Parallel Nsight 1.5 RC with Visual Studio 2010 support
I'm excited to see that the Parallel Nsight 1.5 Release Candidate build (v1.5.10257) is now available at the Parallel Nsight support site. The version introduces compatibility with Visual Studio 2010. You can debug, analyse, and profile your applications in Visual Studio 2010 instead of 2008.
Unfortunately, you will still need the Microsoft v9.0 compilers installed in order to compile your CUDA C/C++ code when using Visual Studio 2010. These compilers ship with Visual Studio 2008, and older versions of the Microsoft Windows SDK.
New Features in Parallel Nsight 1.5 RC:
All:
* Support for Microsoft Visual Studio 2010 in all Parallel Nsight components
* Requires the 260.61 driver (available from the support site)
* Bug fixes and stability improvements
CUDA C/C++ Debugger:
* Support for the CUDA 3.2 RC toolkit
* Support for debugging GPUs using the Tesla Compute Cluster (TCC) driver
* Support for >4GB GPUs, such as the Quadro 6000
* CUDA Memory Checker supports Fermi-based GPUs.
Direct3D Shader Debugger:
* Debugging shaders compiled with the DEBUG flag is now supported.
Direct3D Graphics Inspector:
* Support for GeForce GTX 460 GPUs
* Graphics debug sessions start much faster.
* New Direct3D 11 DXGI texture formats are now supported for visualization.
* Textures used in the current draw call's pixel shader are now viewable directly on the HUD.
Analyzer:
* Support for GeForce GTX 460 GPUs
* NVIDIA Tools Extension (NVTX) events have been improved with color and payload.
* NVIDIA Tools Extension (NVTX) API calls for naming threads, CUDA contexts and other resources
* GPU-side draw call workloads from OpenGL and Direct3D are now traced.
The full release notes can be found at Parallel Nsight support site.
Unfortunately, you will still need the Microsoft v9.0 compilers installed in order to compile your CUDA C/C++ code when using Visual Studio 2010. These compilers ship with Visual Studio 2008, and older versions of the Microsoft Windows SDK.
New Features in Parallel Nsight 1.5 RC:
All:
* Support for Microsoft Visual Studio 2010 in all Parallel Nsight components
* Requires the 260.61 driver (available from the support site)
* Bug fixes and stability improvements
CUDA C/C++ Debugger:
* Support for the CUDA 3.2 RC toolkit
* Support for debugging GPUs using the Tesla Compute Cluster (TCC) driver
* Support for >4GB GPUs, such as the Quadro 6000
* CUDA Memory Checker supports Fermi-based GPUs.
Direct3D Shader Debugger:
* Debugging shaders compiled with the DEBUG flag is now supported.
Direct3D Graphics Inspector:
* Support for GeForce GTX 460 GPUs
* Graphics debug sessions start much faster.
* New Direct3D 11 DXGI texture formats are now supported for visualization.
* Textures used in the current draw call's pixel shader are now viewable directly on the HUD.
Analyzer:
* Support for GeForce GTX 460 GPUs
* NVIDIA Tools Extension (NVTX) events have been improved with color and payload.
* NVIDIA Tools Extension (NVTX) API calls for naming threads, CUDA contexts and other resources
* GPU-side draw call workloads from OpenGL and Direct3D are now traced.
The full release notes can be found at Parallel Nsight support site.
Monday, 2 August 2010
Apply CUDA to solve a 1D heat transfer problem
News - On 27th June, 2010 NVIDIA released CUDA 3.1 and on 21st July, released Parallel Nsight 1.0. The download sites for CUDA Toolkit 3.1 and NVIDIA Parallel Nsight 1.0 are here and here, respectively.
I recently wrote a small piece of code using CUDA to solve a 1D heat transfer problem. The heat transfer happens along the material whose properties are density ρ = 930 kg/m3, specific heat Cp = 1340 J/(kg K) and thermal conductivity k = 0.19 W/(m K). As shown in the figure below, the computation region is illustrated by the thick orange line; the total distance is 1.6 m. There are two boundary conditions attached: at the left end, the temperature is fixed to be 0 oC, while at the right end, a heat flux q = 10 W/m2 is imposed.

If the initial temperature for the entire region is 0 oC, I want to calculate the temperature distribution along the region after 10 seconds' heat propogation.
In the previous figure, the governing heat equation, in partial differential form, has been given. It is then discretised for the internal region, i.e. the orange line, and the right end boundary, which is redly circled, respectively. In the computation, I discretised the entire distance, 1.6 m, into 32768 elements - within CUDA, 64 blocks can be used to handle these elements. On the other hand, for the time marching iteration, the time step can be determined as
^2/4\alpha)
in which α is the thermal diffusivity.
The calculation results, with the help of CUDA and based on float operation, are depicted as

The temperature values for x < 1.5926 m are all zero; therefore they are neglected in the picture. In order to verify the results, the same calculation was also implemented onto CPU and even COMSOL software. The implementation on CPU gave
The interesting thing concerns us is the code efficiency. Once again, I used CUDA 3.1 on my GeForce 9800 GTX+ and a single core of the Q6600 CPU, and the time durations elapsed on the GPU and the CPU for the same calculation are 1.43 s and 5.04 s, respectively. The speedup is 3.52. This speedup value is not that attractive, but it is actually supposed to be much higher when there are much more discretised elements.
I also record the temperature development, in a transient process, of the right end boundary, at which there is heat flux injected. The 10 seconds development curve is illustrated as

I didn't find an easy way to paste source code onto the blog. If you are interested, please leave a comment and the related code can be shared in any way.
I recently wrote a small piece of code using CUDA to solve a 1D heat transfer problem. The heat transfer happens along the material whose properties are density ρ = 930 kg/m3, specific heat Cp = 1340 J/(kg K) and thermal conductivity k = 0.19 W/(m K). As shown in the figure below, the computation region is illustrated by the thick orange line; the total distance is 1.6 m. There are two boundary conditions attached: at the left end, the temperature is fixed to be 0 oC, while at the right end, a heat flux q = 10 W/m2 is imposed.
If the initial temperature for the entire region is 0 oC, I want to calculate the temperature distribution along the region after 10 seconds' heat propogation.
In the previous figure, the governing heat equation, in partial differential form, has been given. It is then discretised for the internal region, i.e. the orange line, and the right end boundary, which is redly circled, respectively. In the computation, I discretised the entire distance, 1.6 m, into 32768 elements - within CUDA, 64 blocks can be used to handle these elements. On the other hand, for the time marching iteration, the time step can be determined as
in which α is the thermal diffusivity.
The calculation results, with the help of CUDA and based on float operation, are depicted as
The temperature values for x < 1.5926 m are all zero; therefore they are neglected in the picture. In order to verify the results, the same calculation was also implemented onto CPU and even COMSOL software. The implementation on CPU gave
The interesting thing concerns us is the code efficiency. Once again, I used CUDA 3.1 on my GeForce 9800 GTX+ and a single core of the Q6600 CPU, and the time durations elapsed on the GPU and the CPU for the same calculation are 1.43 s and 5.04 s, respectively. The speedup is 3.52. This speedup value is not that attractive, but it is actually supposed to be much higher when there are much more discretised elements.
I also record the temperature development, in a transient process, of the right end boundary, at which there is heat flux injected. The 10 seconds development curve is illustrated as
I didn't find an easy way to paste source code onto the blog. If you are interested, please leave a comment and the related code can be shared in any way.
News - The source code can be found in the new post on porting this CUDA program onto Mac OS X.
Sunday, 11 July 2010
A brief test on the efficiency of a .NET 4.0 parallel code example - Part II
With respect to the article, "A Brief Test on the Efficiency of a .NET 4.0 Parallel Code Example", Daniel Grunwald proposed additional interesting pieces of code to compare. First of all, the LINQ and PLINQ methods are present as
They are the most concise code to implement the computation. However, when the individual calculations are very cheap, for example, this simple multiplication d => d * d, the overhead of delegates and lambda expressions could be largely noticable.
When parallelising an algorithm, it is essential to avoid false sharing. In the previous article I split the raw data array into a group of pieces and compute the sub-summation for each piece. Actually I manually determine the number of the pieces - I did a sensitivity study and found that 16 k pieces are sufficient for a data size less than 32 M; larger data size might need more pieces.
Daniel reminded that, by using an advanced overload of Parallel.For, the work can be distributed into pieces by .NET. The code is as
However this method didn't improve the efficiency as expected, at least not efficient as my manual method grouping the array into 16 k pieces, because of, we believe, the dramatic overhead caused by delegates relatively to the cheap multiply-add operation.
Then the working units can be combined to be slightly heavier to compensate the delegate overhead, for example, processing 1024 elements in each invocation.
Finally, this piece of code becomes the most efficient one we have ever found.
In order to generally look at the comparison between the methods, I, once again, list a table as

and the corresponding curves

Note that, in the comparison, I neglected the methods which have already been proved as inefficient in the previous article for clarity.
Any comments are welcome.
// LINQ (running on single core)
final_sum = data.Sum(d => d * d);
// PLINQ (parallelised)
final_sum = data.AsParallel().Sum(d => d * d);
They are the most concise code to implement the computation. However, when the individual calculations are very cheap, for example, this simple multiplication d => d * d, the overhead of delegates and lambda expressions could be largely noticable.
When parallelising an algorithm, it is essential to avoid false sharing. In the previous article I split the raw data array into a group of pieces and compute the sub-summation for each piece. Actually I manually determine the number of the pieces - I did a sensitivity study and found that 16 k pieces are sufficient for a data size less than 32 M; larger data size might need more pieces.
Daniel reminded that, by using an advanced overload of Parallel.For, the work can be distributed into pieces by .NET. The code is as
// localSum
final_sum = 0;
Parallel.For(0, DATA_SIZE,
() => 0, // initialization for each thread
(i, s, localSum) => localSum + data[i] * data[i], // loop body
localSum => Interlocked.Add(ref final_sum, localSum) // final action for each thread
);
However this method didn't improve the efficiency as expected, at least not efficient as my manual method grouping the array into 16 k pieces, because of, we believe, the dramatic overhead caused by delegates relatively to the cheap multiply-add operation.
Then the working units can be combined to be slightly heavier to compensate the delegate overhead, for example, processing 1024 elements in each invocation.
// localSum & groups
final_sum = 0;
Parallel.For(0, (int)(DATA_SIZE / 1024),
() => 0,
(i, s, localSum) =>
{
int end = (i + 1) * 1024;
for (int j = i * 1024; j < end; j++)
{
localSum += data[j] * data[j];
}
return localSum;
},
localSum => Interlocked.Add(ref final_sum, localSum)
);
Finally, this piece of code becomes the most efficient one we have ever found.
In order to generally look at the comparison between the methods, I, once again, list a table as
and the corresponding curves
Note that, in the comparison, I neglected the methods which have already been proved as inefficient in the previous article for clarity.
Any comments are welcome.
Friday, 2 July 2010
A brief test on the efficiency of a .NET 4.0 parallel code example
As a piece of accompanying work of the article, "A short test on the code efficiency of CUDA and thrust", I published a new parallel code example in C# 4.0 on CodeProject. The new example tests the new parallel programming support provided from .NET 4.0, and the corresponding article can be found as
A Brief Test on the Efficiency of a .NET 4.0 Parallel Code Example
Briefly the test results could be depicted by
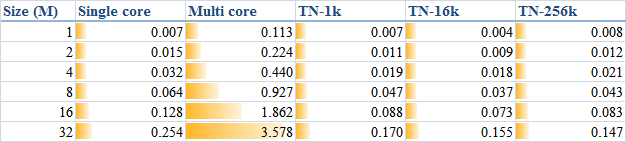
and pictorially
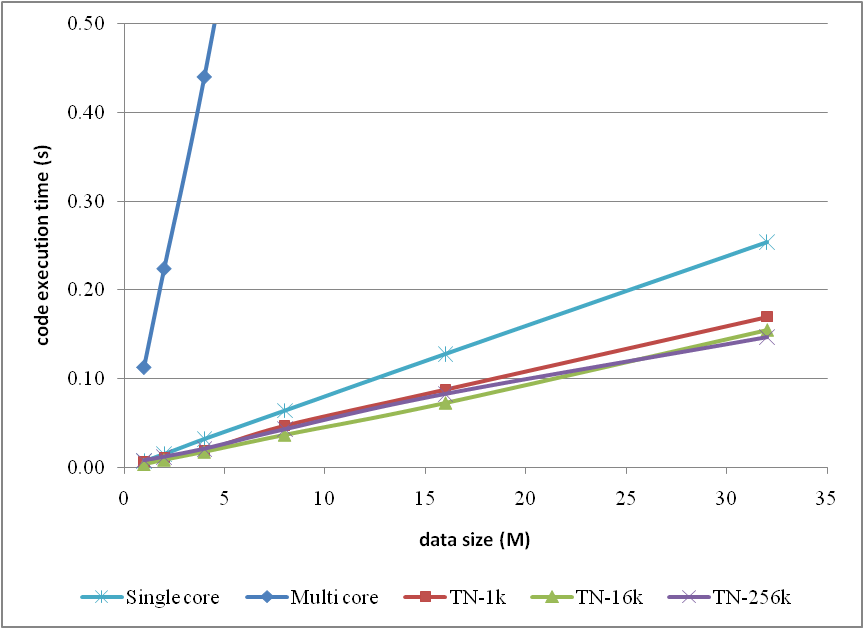
however the original text is suggested to read for more details if you are interested.
I hope the work helps and your comments are welcome.
A Brief Test on the Efficiency of a .NET 4.0 Parallel Code Example
Briefly the test results could be depicted by
and pictorially
however the original text is suggested to read for more details if you are interested.
I hope the work helps and your comments are welcome.
Monday, 28 June 2010
SALOME version 5.1.4 is released
In the good piece of news, CEA/DEN, EDF R&D and OPEN CASCADE are pleased to announce SALOME 5.1.4. It is a public maintenance release that contains the results of planned major and minor improvements and bug fixes against SALOME version 5.1.3 released in December 2009.
This new release of SALOME includes the following important new features and improvements:
SALOME 5.1.4 supports Debian 4.0 Etch 32bit and 64bit; both are Ubuntu compatible. The latest installation wizard packages can be retrieved from the download page of the official site. As feedback from users, the tutorial "Installation of SALOME 5.1.3 on Ubuntu 10.04 (64 bit)" also works with SALOME 5.1.4 on Ubuntu 10.04.
We also look forward to the corresponding Windows version.
SALOME 5.1.4 for tests on windows available
As announced by Adam on 2nd July, 2010, SALOME version 5.1.4 for tests on windows is already available. Please refer to the download page and the how-to-compile page for more details.
This new release of SALOME includes the following important new features and improvements:
- Improved Filling algorithm in Geometry module.
- Mesh scaling operation.
- Split all 3d mesh elements (volumes) to the tetrahedrons.
- Change sub-meshing order for the concurrent sub-meshes.
- Find mesh element closest to the specified point.
- Modify point markers in Mesh and Post-Pro modules.
- Sort table data (Post-Pro module).
- Using of two vertical axes in the Plot2d viewer.
- Keyboard free interaction style in OCC viewer.
- New features in YACS module.
- And more … see SALOME 5.1.4 Release Notes for details
SALOME 5.1.4 supports Debian 4.0 Etch 32bit and 64bit; both are Ubuntu compatible. The latest installation wizard packages can be retrieved from the download page of the official site. As feedback from users, the tutorial "Installation of SALOME 5.1.3 on Ubuntu 10.04 (64 bit)" also works with SALOME 5.1.4 on Ubuntu 10.04.
We also look forward to the corresponding Windows version.
SALOME 5.1.4 for tests on windows available
As announced by Adam on 2nd July, 2010, SALOME version 5.1.4 for tests on windows is already available. Please refer to the download page and the how-to-compile page for more details.
Saturday, 22 May 2010
A short test on the code efficiency of CUDA and thrust
Introduction
Numerical simulations are always pretty time consuming jobs. Most of these jobs take lots of hours to complete, even though multi-core CPUs are commonly used. Before I can afford a cluster, how to dramatically improve the calculation efficiency on my desktop computers to save computational effort became a critical problem I am facing and dreaming to achieve.
NVIDIA CUDA seems more and more popular and potential to solve the present problem with the power released from GPU. CUDA framework provides a modified C language and with its help my C programming experiences can be re-used to implement numerical algorithms by utilising a GPU. Whilst thrust is a C++ template library for CUDA. thrust is aimed at improving developers' development productivity; however, the code execution efficiency is also of high priority for a numerical job. Someone stated that code execution efficiency could be lost to some extent due to the extra cost from using the library thrust. To judge this precisely, I did a series of basic tests in order to explore the truth. Basically, that is the purpose of this article.
My personal computer is a Intel Q6600 quad core CPU plus 3G DDR2 800M memory. Although I don't have good hard drives, marked only 5.1 in Windows 7 32 bit, I think in this test of the calculation of the summation of squares, the access to hard drives might not be significant. The graphic card used is a GeForce 9800 GTX+ with 512M GDDR3 memory. The card is shown as

Algorithm in raw CUDA
The test case I used is solving the summation of squares of an array of integers (random numbers ranged from 0 to 9), and, as I mentioned, a GeForce 9800 GTX+ graphic card running within Windows 7 32-bit system was employed for the testing. If in plain C language, the summation could be implemented by the following loop code, which is then executed on a CPU core:
Obviously, it is a serial computation. The code is executed in a serial stream of instructions. In order to utilise the power of CUDA, the algorithm has to be parallelised, and the more parallelisation are realised, the more potential power will be explored. With the help of my basic understanding on CUDA, I split the data into different groups and then used the equivalent number of threads on the GPU to calculate the summation of the squares of each group. Ultimately results from all the groups are added together to obtain the final result.
The algorithm designed is briefly shown in the figure
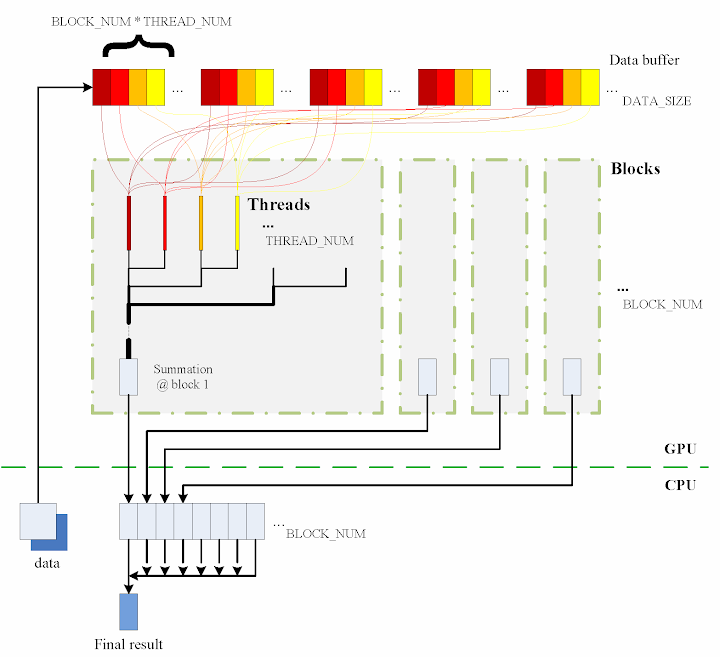
The consecutive steps are:
1. Copy data from the CPU memory to the GPU memory.
2. Totally BLOCK_NUM blocks are used, and in each block THREAD_NUM threads are produced to perform the calculation. In practice, I used THREAD_NUM = 512, which is the greatest allowed thread number in a block of CUDA. Thereby, the raw data are seperated into DATA_SIZE / (BLOCK_NUM * THREAD_NUM) groups.
3. The access to the data buffer is designed as consecutive, otherwise the efficiency will be reduced.
4. Each thread does its corresponding calculation.
5. By using shared memory in the blocks, sub summation can be done in each block. Also, the sub summation is parallelised to achieve as high execution speed as possible. Please refer to the source code regarding the details of this part.
6. The BLOCK_NUM sub summation results for all the blocks are copied back to the CPU side, and they are then added together to obtain the final value
Regarding the procedure, function QueryPerformanceCounter records the code execution duration, which is then used for comparison between the different implementations. Before each call of QueryPerformanceCounter, CUDA function cudaThreadSynchronize() is called to make sure that all computations on the GPU are really finished. (Please refer to the CUDA Best Practices Guide §2.1.)
Algorithm in thrust
The application of the library thrust could make the CUDA code as simple as a plain C++ one. The usage of the library is also compatible with the usage of STL (Standard Template Library) of C++. For instance, the code for the calculation on GPU utilising thrust support is scratched like this:
thrust::generate is used to generate the random data, for which the functor random is defined in advance. random was customised to generate a random integer ranged from 0 to 9.
In comparison with the random number generation without thrust, the code could however not be as elegant.
Similarly square is a transformation functor taking one argument. Please refer to the source code for its definition. square was defined for __host__ __device__ and thus it can be used for both the CPU and the GPU sides.
That is all for the thrust based code. Is it concise enough? :) Here function QueryPerformanceCounter also records the code duration. On the other hand, the host_vector data is operated on CPU to compare. Using the code below, the summation is performed by the CPU end:
I also tested the performance if use thrust::host_vector<int> data as a plain array. This is supposed to cost more overhead, I thought, but we might be curious to know how much. The corresponding code is listed as
The execution time was recorded to compare as well.
Test results on GPU & CPU
The previous experiences show that GPU surpasses CPU when massive parallel computation is realised. When DATA_SIZE increases, the potential of GPU calculation will be gradually released. This is predictable. Moreover, do we lose efficiency when we apply thrust? I guess so, since there is extra cost brought, but do we lose much? We have to judge from the comparison results.
When DATA_SIZE increases from 1 M to 32 M (1 M equals to 1 * 1024 * 1024), the results obtained are illustrated as the table
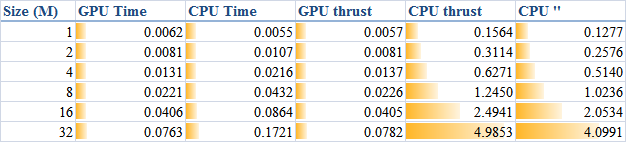
The descriptions of the items are:
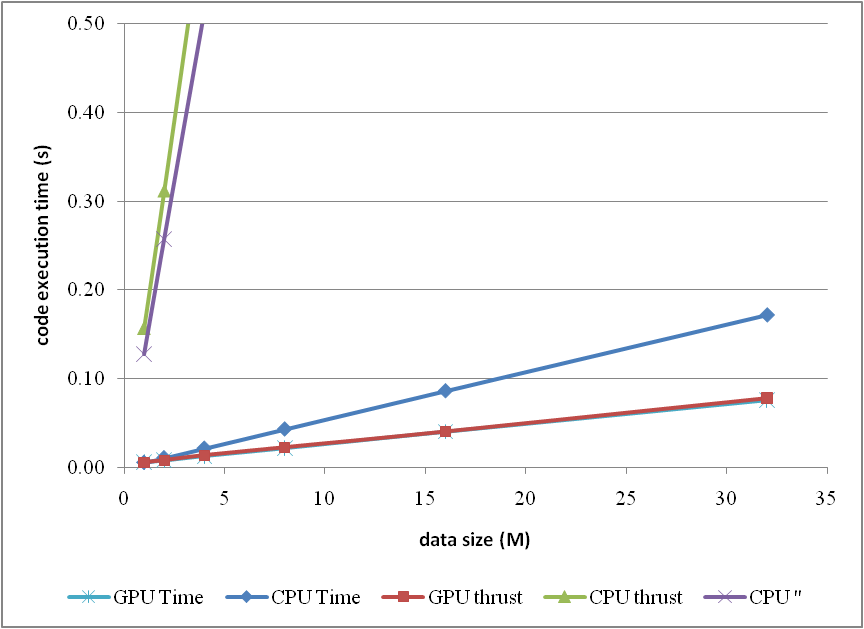
or compare them by the column figure
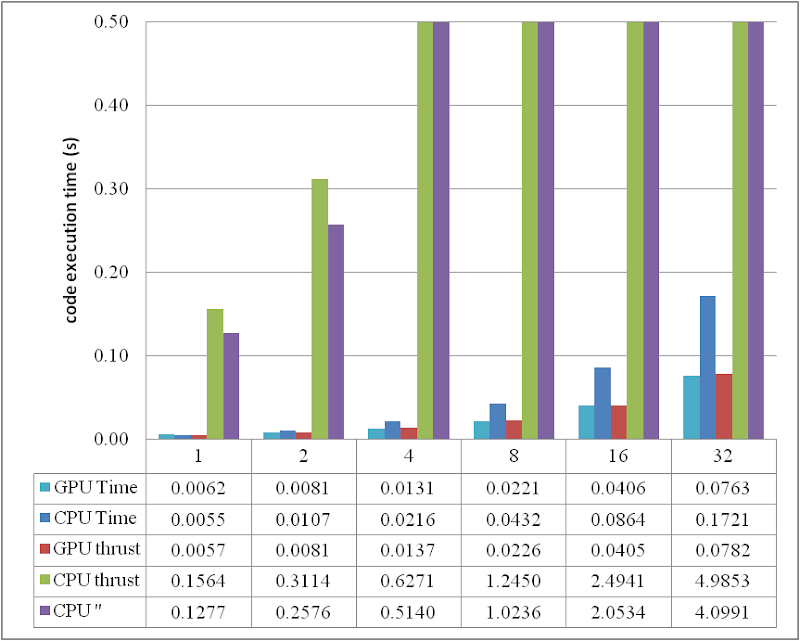
The speedup of GPU to CPU is obvious when DATA_SIZE is more than 4 M. Actually with greater data size, much better performance speedup can be obtained. Interestingly, in this region, the cost of using thrust is quite small, which can even be neglected. However, on the other hand, don't use thrust on the CPU side, neither thrust::transform_reduce method nor a plain loop on a thrust::host_vector; according to the figures, the cost brought is huge. Use a plain array and a loop instead.
From the comparison figure, we found that the application of thrust not only simplifies the code of CUDA computation, but also compensates the loss of efficiency when DATA_SIZE is relatively small. Therefore, it is strongly recommended.
Conclusion
Based on the tests performed, apparently, by employing parallelism, GPU shows greater potential than CPU does, especially for those calculations which contains much more parallel elements. This article also found that the application of thrust does not reduce the code execution efficiency on the GPU side, but brings dramatical negtive changes in the efficiency on the CPU side. Consequently, it is better using plain arrays for CPU calculations.
In conclusion, the usage of thrust feels pretty good, because it improves the code efficiency, and with employing thrust, the CUDA code can be so concise and rapidly developed.
Numerical simulations are always pretty time consuming jobs. Most of these jobs take lots of hours to complete, even though multi-core CPUs are commonly used. Before I can afford a cluster, how to dramatically improve the calculation efficiency on my desktop computers to save computational effort became a critical problem I am facing and dreaming to achieve.
NVIDIA CUDA seems more and more popular and potential to solve the present problem with the power released from GPU. CUDA framework provides a modified C language and with its help my C programming experiences can be re-used to implement numerical algorithms by utilising a GPU. Whilst thrust is a C++ template library for CUDA. thrust is aimed at improving developers' development productivity; however, the code execution efficiency is also of high priority for a numerical job. Someone stated that code execution efficiency could be lost to some extent due to the extra cost from using the library thrust. To judge this precisely, I did a series of basic tests in order to explore the truth. Basically, that is the purpose of this article.
My personal computer is a Intel Q6600 quad core CPU plus 3G DDR2 800M memory. Although I don't have good hard drives, marked only 5.1 in Windows 7 32 bit, I think in this test of the calculation of the summation of squares, the access to hard drives might not be significant. The graphic card used is a GeForce 9800 GTX+ with 512M GDDR3 memory. The card is shown as
Algorithm in raw CUDA
The test case I used is solving the summation of squares of an array of integers (random numbers ranged from 0 to 9), and, as I mentioned, a GeForce 9800 GTX+ graphic card running within Windows 7 32-bit system was employed for the testing. If in plain C language, the summation could be implemented by the following loop code, which is then executed on a CPU core:
int final_sum = 0;
for (int i = 0; i < DATA_SIZE; i++) {
final_sum += data[i] * data[i];
}Obviously, it is a serial computation. The code is executed in a serial stream of instructions. In order to utilise the power of CUDA, the algorithm has to be parallelised, and the more parallelisation are realised, the more potential power will be explored. With the help of my basic understanding on CUDA, I split the data into different groups and then used the equivalent number of threads on the GPU to calculate the summation of the squares of each group. Ultimately results from all the groups are added together to obtain the final result.
The algorithm designed is briefly shown in the figure
The consecutive steps are:
1. Copy data from the CPU memory to the GPU memory.
cudaMemcpy(gpudata, data, sizeof(int) * DATA_SIZE, cudaMemcpyHostToDevice);
2. Totally BLOCK_NUM blocks are used, and in each block THREAD_NUM threads are produced to perform the calculation. In practice, I used THREAD_NUM = 512, which is the greatest allowed thread number in a block of CUDA. Thereby, the raw data are seperated into DATA_SIZE / (BLOCK_NUM * THREAD_NUM) groups.
3. The access to the data buffer is designed as consecutive, otherwise the efficiency will be reduced.
4. Each thread does its corresponding calculation.
shared[tid] = 0;
for (int i = bid * THREAD_NUM + tid; i < DATA_SIZE; i += BLOCK_NUM * THREAD_NUM) {
shared[tid] += num[i] * num[i];
}
5. By using shared memory in the blocks, sub summation can be done in each block. Also, the sub summation is parallelised to achieve as high execution speed as possible. Please refer to the source code regarding the details of this part.
6. The BLOCK_NUM sub summation results for all the blocks are copied back to the CPU side, and they are then added together to obtain the final value
cudaMemcpy(&sum, result, sizeof(int) * BLOCK_NUM, cudaMemcpyDeviceToHost);
int final_sum = 0;
for (int i = 0; i < BLOCK_NUM; i++) {
final_sum += sum[i];
}
Regarding the procedure, function QueryPerformanceCounter records the code execution duration, which is then used for comparison between the different implementations. Before each call of QueryPerformanceCounter, CUDA function cudaThreadSynchronize() is called to make sure that all computations on the GPU are really finished. (Please refer to the CUDA Best Practices Guide §2.1.)
Algorithm in thrust
The application of the library thrust could make the CUDA code as simple as a plain C++ one. The usage of the library is also compatible with the usage of STL (Standard Template Library) of C++. For instance, the code for the calculation on GPU utilising thrust support is scratched like this:
thrust::host_vector<int> data(DATA_SIZE);
srand(time(NULL));
thrust::generate(data.begin(), data.end(), random());
cudaThreadSynchronize();
QueryPerformanceCounter(&elapsed_time_start);
thrust::device_vector<int> gpudata = data;
int final_sum = thrust::transform_reduce(gpudata.begin(), gpudata.end(),
square<int>(), 0, thrust::plus<int>());
cudaThreadSynchronize();
QueryPerformanceCounter(&elapsed_time_end);
elapsed_time = (double)(elapsed_time_end.QuadPart - elapsed_time_start.QuadPart)
/ frequency.QuadPart;
printf("sum (on GPU): %d; time: %lf\n", final_sum, elapsed_time);
thrust::generate is used to generate the random data, for which the functor random is defined in advance. random was customised to generate a random integer ranged from 0 to 9.
// define functor for
// random number ranged in [0, 9]
class random
{
public:
int operator() ()
{
return rand() % 10;
}
};
In comparison with the random number generation without thrust, the code could however not be as elegant.
// generate random number ranged in [0, 9]
void GenerateNumbers(int * number, int size)
{
srand(time(NULL));
for (int i = 0; i < size; i++) {
number[i] = rand() % 10;
}
}
Similarly square is a transformation functor taking one argument. Please refer to the source code for its definition. square was defined for __host__ __device__ and thus it can be used for both the CPU and the GPU sides.
// define transformation f(x) -> x^2
template <typename T>
struct square
{
__host__ __device__
T operator() (T x)
{
return x * x;
}
};
That is all for the thrust based code. Is it concise enough? :) Here function QueryPerformanceCounter also records the code duration. On the other hand, the host_vector data is operated on CPU to compare. Using the code below, the summation is performed by the CPU end:
QueryPerformanceCounter(&elapsed_time_start);
final_sum = thrust::transform_reduce(data.begin(), data.end(),
square<int>(), 0, thrust::plus<int>());
QueryPerformanceCounter(&elapsed_time_end);
elapsed_time = (double)(elapsed_time_end.QuadPart - elapsed_time_start.QuadPart)
/ frequency.QuadPart;
printf("sum (on CPU): %d; time: %lf\n", final_sum, elapsed_time);
I also tested the performance if use thrust::host_vector<int> data as a plain array. This is supposed to cost more overhead, I thought, but we might be curious to know how much. The corresponding code is listed as
final_sum = 0;
for (int i = 0; i < DATA_SIZE; i++)
{
final_sum += data[i] * data[i];
}
printf("sum (on CPU): %d; time: %lf\n", final_sum, elapsed_time);
The execution time was recorded to compare as well.
Test results on GPU & CPU
The previous experiences show that GPU surpasses CPU when massive parallel computation is realised. When DATA_SIZE increases, the potential of GPU calculation will be gradually released. This is predictable. Moreover, do we lose efficiency when we apply thrust? I guess so, since there is extra cost brought, but do we lose much? We have to judge from the comparison results.
When DATA_SIZE increases from 1 M to 32 M (1 M equals to 1 * 1024 * 1024), the results obtained are illustrated as the table
The descriptions of the items are:
- GPU Time: execution time of the raw CUDA code;
- CPU Time: execution time of the plain loop code running on the CPU;
- GPU thrust: execution time of the CUDA code with thrust;
- CPU thrust: execution time of the CPU code with thrust;
- CPU '': execution time of the plain loop code based on thrust::
host_vector.
or compare them by the column figure
The speedup of GPU to CPU is obvious when DATA_SIZE is more than 4 M. Actually with greater data size, much better performance speedup can be obtained. Interestingly, in this region, the cost of using thrust is quite small, which can even be neglected. However, on the other hand, don't use thrust on the CPU side, neither thrust::transform_reduce method nor a plain loop on a thrust::host_vector; according to the figures, the cost brought is huge. Use a plain array and a loop instead.
From the comparison figure, we found that the application of thrust not only simplifies the code of CUDA computation, but also compensates the loss of efficiency when DATA_SIZE is relatively small. Therefore, it is strongly recommended.
Conclusion
Based on the tests performed, apparently, by employing parallelism, GPU shows greater potential than CPU does, especially for those calculations which contains much more parallel elements. This article also found that the application of thrust does not reduce the code execution efficiency on the GPU side, but brings dramatical negtive changes in the efficiency on the CPU side. Consequently, it is better using plain arrays for CPU calculations.
In conclusion, the usage of thrust feels pretty good, because it improves the code efficiency, and with employing thrust, the CUDA code can be so concise and rapidly developed.
ps - This post can also be referred from one of my articles published on CodeProject, "A brief test on the code efficiency of CUDA and thrust", which could be more complete and source code is attached as well. Any comments are sincerely welcome.
Additionally, the code was built and tested in Windows 7 32 bit plus Visual Studio 2008, CUDA 3.0 and the latest thrust 1.2. One also needs a NVIDIA graphic card as well as CUDA toolkit to run the programs. For instructions on installing CUDA, please refer to its official site CUDA Zone.
Additionally, the code was built and tested in Windows 7 32 bit plus Visual Studio 2008, CUDA 3.0 and the latest thrust 1.2. One also needs a NVIDIA graphic card as well as CUDA toolkit to run the programs. For instructions on installing CUDA, please refer to its official site CUDA Zone.
Monday, 22 March 2010
Gambit example: model a 2D channel
"CFD example: laminar flow along a 2D channel" applied SALOME to model and mesh a 2D channel geometry for Code_Saturne to perform the simulation. However, someone likes to use Gambit, a product from ANSYS Fluent, and of course, the same example can also be made with the help of Gambit. Furthermore, similar to SALOME using Python for automatisation, Gambit has Journal file to automatise the manual procedure. The present post aims to translate the previous example into Gambit Journal file in order to show an illustration for beginners.
Basic instructions
1. comments. A comment line in Gambit Journal is headed with a forward slash, /.
2. variables. One is able to define a variable with a name beginning with $. The variable represents a float point value.
3. arrays. Array names are also begun with $. In Gambit Journal, array is indexed by a 1 based number, which is quoted by a pair of square parenthesis, []. The index range of an array should be given at the definition declaration of the array itself.
4. For the construction method of points, edges and faces, it is quite concise as well. Please refer to the simple example given in the next section.
The example
Once again, according to the philosophy of executing commands on terminals, Gambit Journal scripts are used to illustrate the example.
Define the variables and points, and then construct edges and faces accordingly.
After the geometry is constructed, build the mesh, define the boundaries, and then create a zone corresponding to the 2D face "DUCT". Note that, differing from the SALOME example, here the 2D model is not extruded along the z axis, because originally, I wrote the script for Fluent to use at that moment.
Finally, export the mesh file for future use.
Basic instructions
1. comments. A comment line in Gambit Journal is headed with a forward slash, /.
/ This line is commented.
2. variables. One is able to define a variable with a name beginning with $. The variable represents a float point value.
$length = 0.1
3. arrays. Array names are also begun with $. In Gambit Journal, array is indexed by a 1 based number, which is quoted by a pair of square parenthesis, []. The index range of an array should be given at the definition declaration of the array itself.
declare $points[1 : 3]
$points[1] = 1.0
$points[2] = 0.0
$points[3] = 0.0
4. For the construction method of points, edges and faces, it is quite concise as well. Please refer to the simple example given in the next section.
The example
Once again, according to the philosophy of executing commands on terminals, Gambit Journal scripts are used to illustrate the example.
///////////////////////////////////////////////////////////////////////
/ Geometry construction and meshing creation for a typical
/ 2d channel flow between two infinite parallel plates.
/
/ Written by: salad
/ Manchester, UK
/ 06/12/2009
///////////////////////////////////////////////////////////////////////
/
/ L = 0.1 m, D = 0.005 m
/
/ C --------- B
/ | |
/ --> | |
/ O --------- A
/
/ V_in = 0.05 m/s
/ t = 50 degree C
///////////////////////////////////////////////////////////////////////
Define the variables and points, and then construct edges and faces accordingly.
/ Variable Definition
$length = 0.1
$height = 0.005
/ points
vertex create "O" coordinates 0
vertex create "A" coordinates $length
vertex create "B" coordinates $length $height
vertex create "C" coordinates 0 $height
/ edges
edge create "OA" straight "O" "A"
edge create "AB" straight "A" "B"
edge create "BC" straight "B" "C"
edge create "CO" straight "C" "O"
/ faces
face create "DUCT" wireframe "OA" "AB" "BC" "CO"
After the geometry is constructed, build the mesh, define the boundaries, and then create a zone corresponding to the 2D face "DUCT". Note that, differing from the SALOME example, here the 2D model is not extruded along the z axis, because originally, I wrote the script for Fluent to use at that moment.
/ mesh
edge mesh "CO" intervals 50
edge mesh "OA" intervals 250
face mesh "DUCT"
/ boundary
physics create "inlet" btype "VELOCITY_INLET" edge "CO"
physics create "bottom" btype "WALL" edge "OA"
physics create "top" btype "WALL" edge "BC"
physics create "outlet" btype "PRESSURE_OUTLET" edge "AB"
/ zones
physics create "duct_v" ctype "FLUID" face "DUCT"
Finally, export the mesh file for future use.
/ export
export uns "2d_duct_flow.msh"
Friday, 29 January 2010
Installation of OpenFOAM 1.6 on Ubuntu 9.10
OpenFOAM is another open source CFD software. In order to install OpenFOAM onto Ubuntu 9.10, the following packages are necessary.
cmake g++ flex++ bison python qt4-designer binutils-dev zlib1g-dev
Use apt-get to install them before trying to install and use OpenFOAM.
A very brief introduction on the compilation
1. Download the related packages, including the source pack and the binary pack. Double precision is recommended.
2. Create a directory OpenFOAM under $HOME (or at other locations if you prefer), move the downloaded packages into it, and then execute
3. After the files extracted, source the file OpenFOAM-1.6/etc/bashrc.
For convenience, a sentence could be incorporated into the user config file ~/.bashrc to avoid executing the command above manually in the future.
4. Compile ParaView. Ship into OpenFOAM/ThirdParty-1.6 and execute
5. Link OpenFOAM ParaView reader and ParaView.
The Windows version
"openfoam-mswin" is a project to provide an OpenFOAM binary release for MS windows. The project is hosted on SourceForge, and a self-install file for Windows can then be downloaded from its SourceForge site. With its help, it is easier to install and use OpenFOAM if Linux experience is absent.
cmake g++ flex++ bison python qt4-designer binutils-dev zlib1g-dev
Use apt-get to install them before trying to install and use OpenFOAM.
:/$ sudo apt-get install cmake g++ flex++ bison python qt4-designer binutils-dev zlib1g-dev
A very brief introduction on the compilation
1. Download the related packages, including the source pack and the binary pack. Double precision is recommended.
2. Create a directory OpenFOAM under $HOME (or at other locations if you prefer), move the downloaded packages into it, and then execute
# ship into $HOME/OpenFOAM/
:/$ tar xzvf OpenFOAM-1.6.General.gtgz
:/$ tar xzvf ThirdParty-1.6.General.gtgz
:/$ tar xzvf OpenFOAM-1.6.linuxGccDPOpt.gtgz
:/$ tar xzvf ThirdParty-1.6.linuxGcc.gtgz
3. After the files extracted, source the file OpenFOAM-1.6/etc/bashrc.
# at $HOME/OpenFOAM/
:/$ source OpenFOAM-1.6/etc/bashrc
For convenience, a sentence could be incorporated into the user config file ~/.bashrc to avoid executing the command above manually in the future.
source $HOME/OpenFOAM/OpenFOAM-1.6/etc/bashrc
4. Compile ParaView. Ship into OpenFOAM/ThirdParty-1.6 and execute
sh makeParaView
5. Link OpenFOAM ParaView reader and ParaView.
:/$ cd $FOAM_UTILITIES/postProcessing/graphics/PV3FoamReader
:/$ ./Allwclean
:/$ ./Allwmake
The Windows version
"openfoam-mswin" is a project to provide an OpenFOAM binary release for MS windows. The project is hosted on SourceForge, and a self-install file for Windows can then be downloaded from its SourceForge site. With its help, it is easier to install and use OpenFOAM if Linux experience is absent.
Monday, 7 December 2009
SALOME, on the way to cross-platform
SALOME running on Mac OS X
Unfortunately, I don't have a Mac machine and thus I didn't get any experience on a Mac, because of its big price :(. However, I do suggest you read here if you want to use SALOME on Mac OS X. There is also a nice picture which might bring some hope if you are facing problems.

SALOME version 5.1.2 for Windows platform
Although I knew SALOME was ported onto Windows platform, I didn't try, because regarding such a huge and complicated software package, I don't expect more. However, I also admit that if the Windows version can run well, it is significantly helpful to those who are not familiar with Linux enough. Then I tried this Windows version and, surprisingly, found it works like a charm. Python, C/C++, QT and all of the cross-platform languages and libraries do give us an option to create programs which is compatible with both Linux and Windows simultaneously. It is totally awesome.
Ok, let's look at this SALOME for Windows. From
http://files.salome-platform.org/cea/adam/salomewindows/download/
the zip package (and a patch file) can be downloaded. Unpack the package to wherever you like, run the bat file release\salome.bat, and SALOME will be launched. Its appearance is exactly the same as in Linux. I tried to load a python script I previously wrote. It worked very well.
The patch file salome_utils.py should be copied to the directory release\modules\KERNEL_INSTALL\bin\salome.
Do you want a go?
SALOME version 5.1.3 for tests on Windows
SALOME version 5.1.3 is recently released by CEA/DEN, EDF R&D and OPEN CASCADE on 14th Dec. 2009. As mentioned, it is a public maintenance release that contains planned major and minor improvements plus bug fixes against SALOME version 5.1.2. Read the news for more details and the download page is here.
According to the message published on the SALOME forum, A SALOME 5.1.3 for tests on Windows came to be available on 18th Dec. 2009. The download address is still at http://files.salome-platform.org/cea/adam/salomewindows/download/. The previous version 5.1.2 was moved to the directory "old". Addtionally, a list of known problems can be found at http://sites.google.com/site/wikisalomeplatform/Home/salome-windows/salome-windows-errata.
Probably, for those who are looking forward to using SALOME on Windows, screenshots could bring more pleasant surprises. The screenshots below were taken from Windows 7.

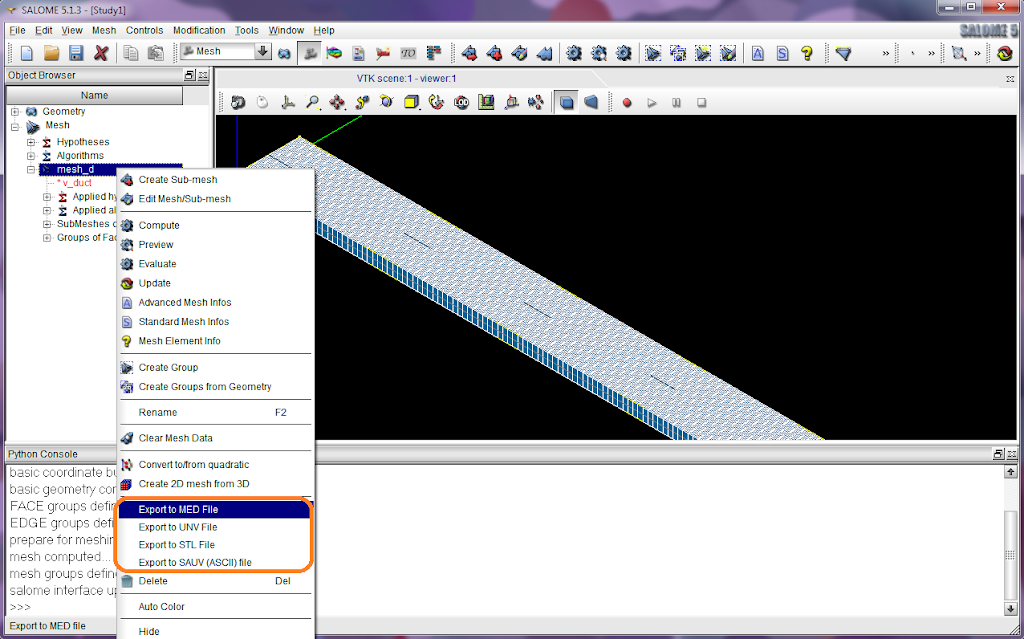
You can also compile SALOME on windows if you like. See a howto at http://sites.google.com/site/wikisalomeplatform/Home/salome-windows/5-1-3/howto-compile.
Unfortunately, I don't have a Mac machine and thus I didn't get any experience on a Mac, because of its big price :(. However, I do suggest you read here if you want to use SALOME on Mac OS X. There is also a nice picture which might bring some hope if you are facing problems.
SALOME version 5.1.2 for Windows platform
Although I knew SALOME was ported onto Windows platform, I didn't try, because regarding such a huge and complicated software package, I don't expect more. However, I also admit that if the Windows version can run well, it is significantly helpful to those who are not familiar with Linux enough. Then I tried this Windows version and, surprisingly, found it works like a charm. Python, C/C++, QT and all of the cross-platform languages and libraries do give us an option to create programs which is compatible with both Linux and Windows simultaneously. It is totally awesome.
Ok, let's look at this SALOME for Windows. From
http://files.salome-platform.org/cea/adam/salomewindows/download/
the zip package (and a patch file) can be downloaded. Unpack the package to wherever you like, run the bat file release\salome.bat, and SALOME will be launched. Its appearance is exactly the same as in Linux. I tried to load a python script I previously wrote. It worked very well.
The patch file salome_utils.py should be copied to the directory release\modules\KERNEL_INSTALL\bin\salome.
Do you want a go?
SALOME version 5.1.3 for tests on Windows
SALOME version 5.1.3 is recently released by CEA/DEN, EDF R&D and OPEN CASCADE on 14th Dec. 2009. As mentioned, it is a public maintenance release that contains planned major and minor improvements plus bug fixes against SALOME version 5.1.2. Read the news for more details and the download page is here.
According to the message published on the SALOME forum, A SALOME 5.1.3 for tests on Windows came to be available on 18th Dec. 2009. The download address is still at http://files.salome-platform.org/cea/adam/salomewindows/download/. The previous version 5.1.2 was moved to the directory "old". Addtionally, a list of known problems can be found at http://sites.google.com/site/wikisalomeplatform/Home/salome-windows/salome-windows-errata.
Probably, for those who are looking forward to using SALOME on Windows, screenshots could bring more pleasant surprises. The screenshots below were taken from Windows 7.
You can also compile SALOME on windows if you like. See a howto at http://sites.google.com/site/wikisalomeplatform/Home/salome-windows/5-1-3/howto-compile.
Sunday, 9 August 2009
Linux/Ubuntu on a Lenovo ThinkPad
I installed Ubuntu 9.04 onto my ThinkPad T61. ThinkPad series is famous to be Linux friendly, and also because the big improvement of Linux/Ubuntu, after I finished the installation, I found most hardware drivers are installed and ready to use, even including the Fn keys. It is a shame that I still have more than 569 MB ThinkPad driver files for Windows XP stored on my harddisk.
* CPU Temperature and the Cooling Fans
A very useful tool GNOME Sensors Applet can indicate CPU, harddisk and GPU temperatures as well as cooling fan speed. Use apt-get to install the applet and monitor what you want.
Although it is BIOS's responsibility to optimize the cooling fan speed in order to limit the temperatures, another tool ThinkPad Fan Control (tp-fan) allow you to control the fan speed manually. To install tp-fan, enable its PPA source, and then use apt-get
However, it is not recommended to use tp-fan to adjust the temperature thresholds controlling the fan running level.
Actually, by looking up proc files under /proc/acpi/ibm ThinkPad runtime status can be obtained, including the cooling fan. Then it is known that the fan has 0-7 eight levels to be running at.
* FingerPrint Reader
Install ThinkFinger to use the FingerPrint Reader device.
Its usage is detailedly described on "Install ThinkFinger on Ubuntu".
* Harddisk Active Protection System (APS)
First of all, it is necessary to download these packages. You have to compile them manually except the third one, the script. Actually, the first one is already available in the system, and the second one can be easily installed by using apt-get; however, these binary versions cannot work as expected.
Please refer to Reference 1.
2. Use typical "./configure --prefix=/usr/ && make && sudo make install" to build hdapsd. hdapsd will be installed into /usr/sbin/. hdaps-gl, in package hdaps-utils, can be used to test hdaps. Refer to Reference 2.
3. Make the hdapsd script executable, copy it into /etc/init.d/, and then run it.
4. Build the GNOME hdaps applet and install it. Then add the applet onto a GNOME panel. The applet is an indicator to show whether the magnetic head of the harddisk is parked.
5. Refering to Reference 2, smartctl can be used to look up the park times of the magnetic head of harddisks. Among the smartctl output, the last number of the line, which contains "Load_Cycle", is the park times.
This park times has a limitation in an alive harddisk. It implies frequently parking the head is not a good idea either. Therefore, default value for the parameter "SENSITIVITY", 15, is too low. We can make it higher, for example, to 50, by modifying /etc/default/hdapsd.
Actually, on Windows I guess it is also necessary to adjust the 'shock detection sensitivity' lower to 'medium'.

References:
1. Enabling Active Protection System on a ThinkPad T61
2. X200下的HDAPS妖魔鬼怪
* CPU Temperature and the Cooling Fans
A very useful tool GNOME Sensors Applet can indicate CPU, harddisk and GPU temperatures as well as cooling fan speed. Use apt-get to install the applet and monitor what you want.
:/$ sudo apt-get install sensors-applet
Although it is BIOS's responsibility to optimize the cooling fan speed in order to limit the temperatures, another tool ThinkPad Fan Control (tp-fan) allow you to control the fan speed manually. To install tp-fan, enable its PPA source, and then use apt-get
:/$ sudo apt-get install tpfand
However, it is not recommended to use tp-fan to adjust the temperature thresholds controlling the fan running level.
Actually, by looking up proc files under /proc/acpi/ibm ThinkPad runtime status can be obtained, including the cooling fan. Then it is known that the fan has 0-7 eight levels to be running at.
:/$ cat /proc/acpi/ibm/fan
* FingerPrint Reader
Install ThinkFinger to use the FingerPrint Reader device.
:/$ sudo apt-get install thinkfinger-tools
Its usage is detailedly described on "Install ThinkFinger on Ubuntu".
* Harddisk Active Protection System (APS)
First of all, it is necessary to download these packages. You have to compile them manually except the third one, the script. Actually, the first one is already available in the system, and the second one can be easily installed by using apt-get; however, these binary versions cannot work as expected.
- Driver package: tp_smapi-0.40.tgz
- The daemon program: hdapsd-20090401.tar.gz
- Automatic management script: hdapsd
- Applet for the GNOME panel: gnome-hdaps-applet-20081204.tar.gz
:/$ sudo modprobe thinkpad_ec tp_smapi hdaps
Please refer to Reference 1.
2. Use typical "./configure --prefix=/usr/ && make && sudo make install" to build hdapsd. hdapsd will be installed into /usr/sbin/. hdaps-gl, in package hdaps-utils, can be used to test hdaps. Refer to Reference 2.
3. Make the hdapsd script executable, copy it into /etc/init.d/, and then run it.
:/$ chmod +x hdapsd :/$ sudo cp hdapsd /etc/init.d/ :/$ sudo /etc/init.d/hdapsd start
4. Build the GNOME hdaps applet and install it. Then add the applet onto a GNOME panel. The applet is an indicator to show whether the magnetic head of the harddisk is parked.
:/$ sudo apt-get install libpanel-applet2-dev :/$ cd ~/gnome-hdaps-applet-20081204 :/$ gcc $(pkg-config --cflags --libs libpanelapplet-2.0) -o gnome-hdaps-applet gnome-hdaps-applet.c :/$ sudo cp gnome-hdaps-applet /usr/bin/ :/$ sudo mkdir /usr/share/pixmaps/gnome-hdaps-applet/ :/$ sudo cp *.png /usr/share/pixmaps/gnome-hdaps-applet/ :/$ sudo cp GNOME_HDAPS_StatusApplet.server /usr/lib/bonobo/servers/
5. Refering to Reference 2, smartctl can be used to look up the park times of the magnetic head of harddisks. Among the smartctl output, the last number of the line, which contains "Load_Cycle", is the park times.
:/$ sudo apt-get install smartmontools :/$ sudo smartctl -a /dev/sda | grep Load_Cycle
This park times has a limitation in an alive harddisk. It implies frequently parking the head is not a good idea either. Therefore, default value for the parameter "SENSITIVITY", 15, is too low. We can make it higher, for example, to 50, by modifying /etc/default/hdapsd.
# sensitivity SENSITIVITY=50
Actually, on Windows I guess it is also necessary to adjust the 'shock detection sensitivity' lower to 'medium'.
References:
1. Enabling Active Protection System on a ThinkPad T61
2. X200下的HDAPS妖魔鬼怪
Subscribe to:
Posts (Atom)



