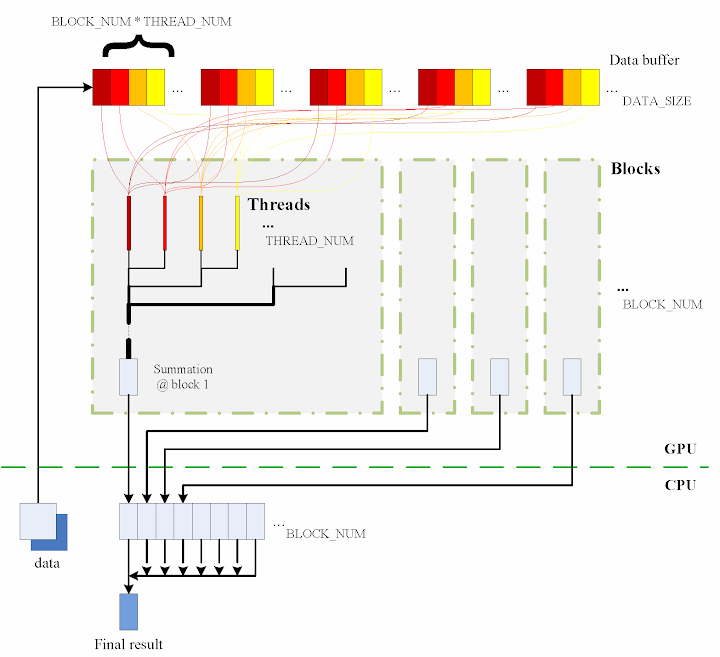
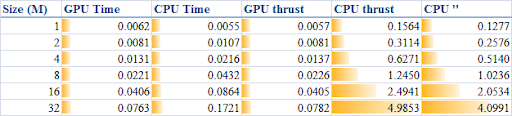
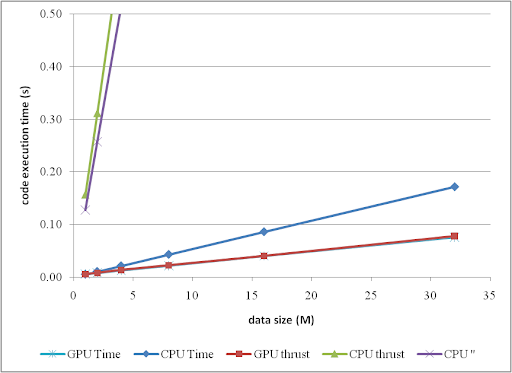
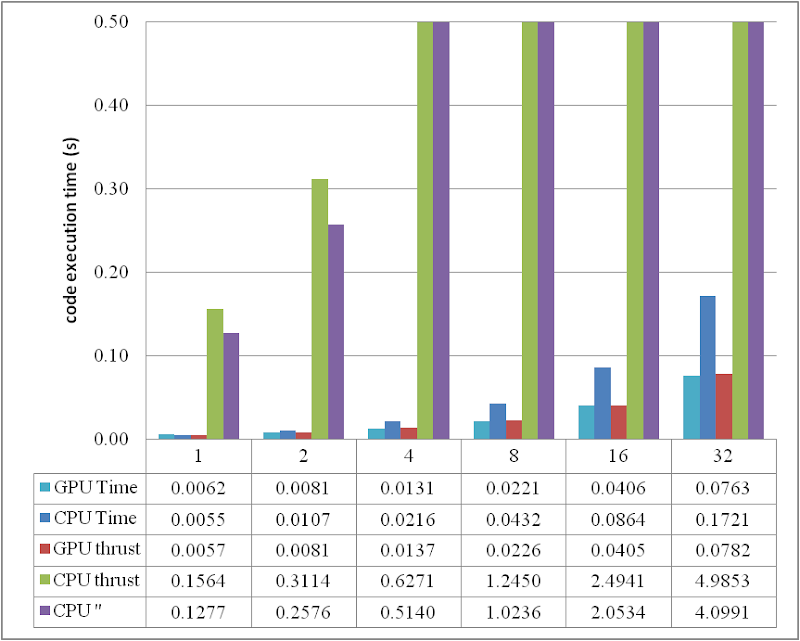
In the past two years, since I started to use Code_Saturne, I compiled the packages over and over whenever I need to use it. I wrote posts and share my experiences in order to save others' precious time from solving all the compilation problems one might meet with. At the same time, I was also thinking, if we could use the standard apt-get to install Code_Saturne, it would be perfect.
salad@ubuntu:~$ sudo apt-get install code-saturne
Reading package lists... Done
Building dependency tree
Reading state information... Done
Package code-saturne is not available, but is referred to by another package.
This may mean that the package is missing, has been obsoleted, or
is only available from another source
E: Package code-saturne has no installation candidate
David said the code-saturne package is only available in Debian testing. Therefore, I add two lines into my source configuration /etc/apt/sources.list: (Please select a corresponding source which is fast in your area; you can refer to http://www.debian.org/mirror/list)
deb http://mirror.ox.ac.uk/debian/ testing main
deb-src http://mirror.ox.ac.uk/debian/ testing main
Then retrieve the list of packages and apt-get install code-saturne
:/$ sudo apt-get update
:/$ sudo apt-get install code-saturne
Gladly, this time I get positive information saying the packages can be installed.
salad@ubuntu:~$ sudo apt-get install code-saturne
Reading package lists... Done
Building dependency tree
Reading state information... Done
The following packages were automatically installed and are no longer required:
qt4-doc libswscale0 libavutil49 libpthread-stubs0 libgl1-mesa-dev
x11proto-kb-dev libqt4-opengl libavcodec52 mesa-common-dev xtrans-dev
x11proto-input-dev libglu1-mesa-dev libdrm-dev libqt4-multimedia qt4-qmake
libgsm1 libxau-dev libschroedinger-1.0-0 libavformat52 libx11-dev
libdirac-encoder0 libxcb1-dev mpi-default-bin libopenjpeg2 x11proto-core-dev
libxdmcp-dev libpthread-stubs0-dev qt4-designer libfaad2
Use 'apt-get autoremove' to remove them.
The following extra packages will be installed:
code-saturne-bin code-saturne-data code-saturne-include ecs libaudio2
libavcodec52 libavformat52 libavutil49 libbft1 libcgns2 libdb4.5
libdirac-encoder0 libdrm-dev libdrm-intel1 libdrm-nouveau1 libdrm-radeon1
libdrm2 libfaad2 libfvm0 libgl1-mesa-dev libglu1-mesa-dev libgsm1
libhdf5-openmpi-1.8.4 libmedc1 libmei0 libmng1 libmysqlclient16 libncursesw5
libopenjpeg2 libpthread-stubs0 libpthread-stubs0-dev libqt4-assistant
libqt4-dbus libqt4-designer libqt4-help libqt4-multimedia libqt4-network
libqt4-opengl libqt4-phonon libqt4-qt3support libqt4-script
libqt4-scripttools libqt4-sql libqt4-sql-mysql libqt4-sql-sqlite libqt4-svg
libqt4-test libqt4-webkit libqt4-xml libqt4-xmlpatterns libqtcore4 libqtgui4
libschroedinger-1.0-0 libsqlite3-0 libssl0.9.8 libswscale0 libx11-6
libx11-dev libxau-dev libxau6 libxcb1 libxcb1-dev libxdmcp-dev libxdmcp6
mesa-common-dev mpi-default-bin mysql-common python-qt4 python-sip python2.5
python2.5-minimal qt4-designer qt4-doc qt4-qmake qt4-qtconfig syrthes
x11proto-core-dev x11proto-input-dev x11proto-kb-dev xtrans-dev
Suggested packages:
nas libmed-tools libmed-doc libqt4-dev python-qt4-dbg python2.5-doc
python-profiler qt4-dev-tools
Recommended packages:
paraview
The following NEW packages will be installed
code-saturne code-saturne-bin code-saturne-data code-saturne-include ecs
libaudio2 libavcodec52 libavformat52 libavutil49 libbft1 libcgns2 libdb4.5
libdirac-encoder0 libdrm-dev libfaad2 libfvm0 libgl1-mesa-dev
libglu1-mesa-dev libgsm1 libhdf5-openmpi-1.8.4 libmedc1 libmei0 libmng1
libmysqlclient16 libopenjpeg2 libpthread-stubs0 libpthread-stubs0-dev
libqt4-assistant libqt4-dbus libqt4-designer libqt4-help libqt4-multimedia
libqt4-network libqt4-opengl libqt4-phonon libqt4-qt3support libqt4-script
libqt4-scripttools libqt4-sql libqt4-sql-mysql libqt4-sql-sqlite libqt4-svg
libqt4-test libqt4-webkit libqt4-xml libqt4-xmlpatterns libqtcore4 libqtgui4
libschroedinger-1.0-0 libswscale0 libx11-dev libxau-dev libxcb1-dev
libxdmcp-dev mesa-common-dev mpi-default-bin mysql-common python-qt4
python-sip python2.5 python2.5-minimal qt4-designer qt4-doc qt4-qmake
qt4-qtconfig syrthes x11proto-core-dev x11proto-input-dev x11proto-kb-dev
xtrans-dev
The following packages will be upgraded:
libdrm-intel1 libdrm-nouveau1 libdrm-radeon1 libdrm2 libncursesw5
libsqlite3-0 libssl0.9.8 libx11-6 libxau6 libxcb1 libxdmcp6
11 upgraded, 70 newly installed, 0 to remove and 655 not upgraded.
Need to get 131MB of archives.
After this operation, 245MB of additional disk space will be used.
Do you want to continue [Y/n]?
Accept it and all the related packages will be downloaded and installed. To see if it is really there, type
salad@ubuntu:~$ type code_saturne
code_saturne is hashed (/usr/bin/code_saturne)
salad@ubuntu:~$ code_saturne config
Directories:
dirs.prefix = /usr
dirs.exec_prefix = /usr
dirs.bindir = /usr/bin
dirs.includedir = /usr/include
dirs.libdir = /usr/lib
dirs.datarootdir = /usr/share
dirs.datadir = /usr/share
dirs.pkgdatadir = /usr/share/ncs
dirs.docdir = /usr/share/doc/ncs
dirs.pdfdir = /usr/share/doc/ncs
Auxiliary information:
dirs.ecs_bindir = /usr/bin
dirs.syrthes_prefix = /usr/lib/syrthes/3.4.2
MPI library information:
mpi_lib.type =
mpi_lib.bindir =
mpi_lib.libdir =
Compilers and associated options:
cc = cc
fc = gfortran
cppflags = -D_POSIX_SOURCE -DNDEBUG -I/usr/include/libxml2
cflags = -std=c99 -funsigned-char -pedantic -W -Wall -Wshadow -Wpointer-arith -Wcast-qual -Wcast-align -Wwrite-strings -Wstrict-prototypes -Wmissing-prototypes -Wmissing-declarations -Wnested-externs -Wunused -Wfloat-equal -g -O2 -g -Wall -O2 -funroll-loops -O2 -Wuninitialized
fcflags = -x f95-cpp-input -Wall -Wno-unused -D_CS_FC_HAVE_FLUSH -O
ldflags = -Wl,-export-dynamic -O
libs = -lfvm -lm -lcgns -lmedC -lhdf5 -lmei -lbft -lz -lxml2 -lblas -L/usr/lib/gcc/i486-linux-gnu/4.4.3 -L/usr/lib/gcc/i486-linux-gnu/4.4.3/../../../../lib -L/lib/../lib -L/usr/lib/../lib -L/usr/lib/gcc/i486-linux-gnu/4.4.3/../../.. -lgfortranbegin -lgfortran -lm -ldl
rpath = -Wl,-rpath -Wl,
Compilers and associated options for SYRTHES build:
cc = /usr/bin/gcc
fc = /usr/bin/gfortran
cppflags = -I/usr/lib/syrthes/3.4.2/include
cflags = -O2 -D_FILE_OFFSET_BITS=64 -DHAVE_C_IO
fcflags = -O2 -DHAVE_C_IO -D_FILE_OFFSET_BITS=64
ldflags = -L/usr/lib/syrthes/3.4.2/lib/Linux
libs = -lbft -lz -lsatsyrthes3.4.2_Linux -lsyrthes3.4.2_Linux -L/usr/lib/gcc/i486-linux-gnu/4.4.3 -L/usr/lib/gcc/i486-linux-gnu/4.4.3/../../../../lib -L/lib/../lib -L/usr/lib/../lib -L/usr/lib/gcc/i486-linux-gnu/4.4.3/../../.. -lgfortranbegin -lgfortran -lm
salad@ubuntu:~$ code_saturne create -s STUDY -c CASE
Code_Saturne 2.0.0-rc1 study/case generation
o Creating study 'STUDY'...
o Creating case 'CASE'...
We see the MPI library information is blank, as the package currently miss MPI support (this will hopefully be corrected before final release).
SALOME
Ledru said SALOME has just been uploaded into Debian. (see the first comment of "Installation of SALOME 5.1.3 on Ubuntu 10.04 (64 bit)") That is right; there is a package salome but there is no source containing it. Let's hope for it.
salad@ubuntu:~$ sudo apt-get install salome
Reading package lists... Done
Building dependency tree
Reading state information... Done
Package salome is not available, but is referred to by another package.
This may mean that the package is missing, has been obsoleted, or
is only available from another source
E: Package salome has no installation candidate
ParaView
apt-get install paraview can install paraview 3.4.0 at the moment. Although the latest version is already 3.8.0, a not-quite-old 3.4.0 is pretty enough if want to enjoy the ease of apt-get.
salad@ubuntu:~$ type paraview
paraview is hashed (/usr/bin/paraview)
salad@ubuntu:~$ paraview --version
ParaView3.4