// LINQ (running on single core)
final_sum = data.Sum(d => d * d);
// PLINQ (parallelised)
final_sum = data.AsParallel().Sum(d => d * d);
They are the most concise code to implement the computation. However, when the individual calculations are very cheap, for example, this simple multiplication d => d * d, the overhead of delegates and lambda expressions could be largely noticable.
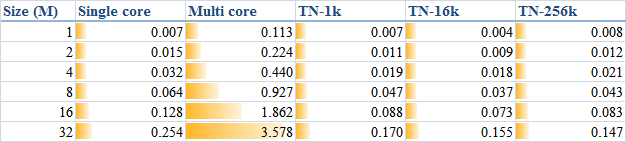
When parallelising an algorithm, it is essential to avoid false sharing. In the previous article I split the raw data array into a group of pieces and compute the sub-summation for each piece. Actually I manually determine the number of the pieces - I did a sensitivity study and found that 16 k pieces are sufficient for a data size less than 32 M; larger data size might need more pieces.
Daniel reminded that, by using an advanced overload of Parallel.For, the work can be distributed into pieces by .NET. The code is as
// localSum
final_sum = 0;
Parallel.For(0, DATA_SIZE,
() => 0, // initialization for each thread
(i, s, localSum) => localSum + data[i] * data[i], // loop body
localSum => Interlocked.Add(ref final_sum, localSum) // final action for each thread
);
However this method didn't improve the efficiency as expected, at least not efficient as my manual method grouping the array into 16 k pieces, because of, we believe, the dramatic overhead caused by delegates relatively to the cheap multiply-add operation.
Then the working units can be combined to be slightly heavier to compensate the delegate overhead, for example, processing 1024 elements in each invocation.
// localSum & groups
final_sum = 0;
Parallel.For(0, (int)(DATA_SIZE / 1024),
() => 0,
(i, s, localSum) =>
{
int end = (i + 1) * 1024;
for (int j = i * 1024; j < end; j++)
{
localSum += data[j] * data[j];
}
return localSum;
},
localSum => Interlocked.Add(ref final_sum, localSum)
);
Finally, this piece of code becomes the most efficient one we have ever found.
In order to generally look at the comparison between the methods, I, once again, list a table as

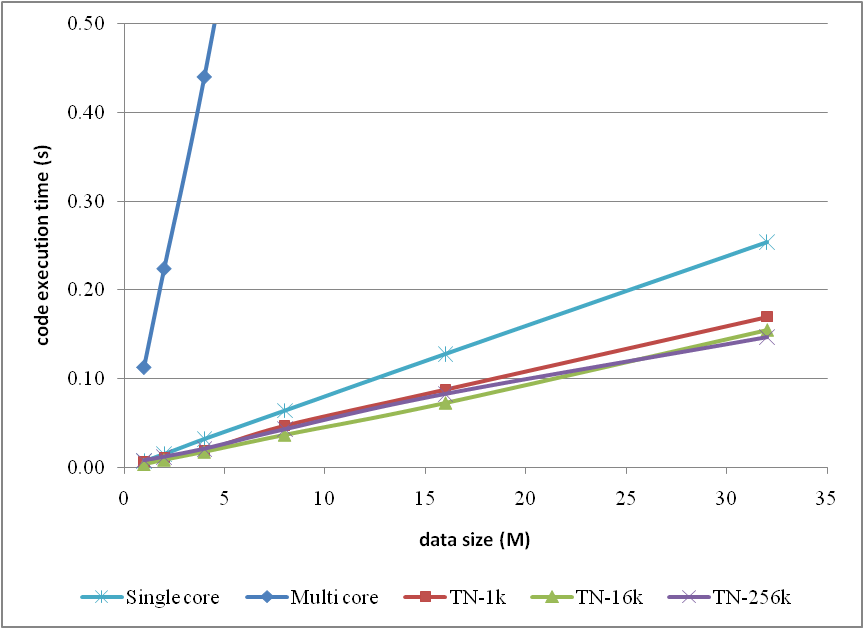
and the corresponding curves

Note that, in the comparison, I neglected the methods which have already been proved as inefficient in the previous article for clarity.
Any comments are welcome.